¿Google Dorks? - Cómo buscar como Hacker


Los Google Dorks suelen aparecer en los cursos de OSINT y pentesting como una lista de “comandos mágicos” , atajos prácticos para encontrar información.
Esa presentación es útil para arrancar, pero también es engañosa: convierte una técnica potente y que depende de conceptos complejos en solo una herramienta de copiar-pegar.
Es por esto que muchos principiantes a pesar de haber revisado el tema nunca terminan por desarrollar todo el mindset necesario para entender: ¿Cuándo usar dorks? ¿Cuáles son las limitaciones? ¿Qué otros comandos puedo generar?
En Purpl3 Cult preferimos otra forma de enseñarte: desmontar y analizar parte a parte cada pieza, entender por qué funcionan las búsquedas avanzadas y cuándo dejan de ser útiles.
Aquí no te daremos solo cheatsheets; te daremos el marco mental para razonar, adaptar y explotar estas técnicas con criterio. Y entender realmente que es lo que estás haciendo para realmente explotar esto y que obtengas beneficio por ello.
¿Qué vas a aprender leyendo este post?
- Cómo funciona realmente un motor de búsqueda: crawlers, estructuras de datos e índices —para que entiendas de dónde sale cada resultado.
- Qué son y cómo se usan los Google Dorks —Separar la señal del ruido.
- Casos prácticos, aplicaciones y la mentalidad analítica necesaria para ejecutar búsquedas que puedas monetizar y otorguen valor.
Lamento que este blog requiera más de 20 segundos de tu atención, pero estoy seguro que si realmente te interesa el tema y aprender a investigar a profundidad en internet, encontrar datos sensibles y monetizar tus habilidades en OSINT podrás leerlo todo ;)
Dicho esto, empecemos.
La Naturaleza de la Web y los Motores de Búsqueda
Para comprender realmente qué hacen los Google Dorks y por qué son tan efectivos, necesitamos primero entender la arquitectura subyacente de la web y cómo los motores de búsqueda la procesan.
Esto tan fundamental es lo que separa a quienes simplemente copian comandos de quienes realmente entienden las implicaciones de lo que están haciendo.
Una página web, en su esencia más fundamental, es un archivo de texto estructurado. Cuando escribimos una URL en nuestro navegador, estamos solicitando a un servidor web que nos envíe este archivo (mediante HTTP), típicamente escrito en HTML (HyperText Markup Language).
Este archivo contiene no solo el contenido visible, sino también metadatos, referencias a otros recursos como hojas de estilo CSS, scripts de JavaScript, imágenes, y crucialmente, enlaces a otras páginas. Esta interconexión mediante hipervínculos es lo que transforma una colección de archivos individuales en la "telaraña mundial" que conocemos como World Wide Web.
El protocolo HTTP (o su versión segura HTTPS) rige estas transacciones de datos entre el cliente (tu navegador) y el servidor (la computadora donde está alojada la página web y contenido que estás solicitando). Cada vez que accedemos a una página, nuestro navegador envía una solicitud HTTP al servidor, que responde con el contenido solicitado si está disponible y el usuario tiene permisos para acceder a él.
Si aún no sabes cómo funciona HTTP recuerda que tenemos un webinar completo y totalmente gratuito sobre el tema:
¿Cómo se descubre el contenido?: Crawling e Indexación
Los motores de búsqueda como Google enfrentan un desafío imponente: hacer "buscable" y accesible el contenido de miles de millones de páginas web.
Para lograr esto, emplean programas conocidos como crawlers, spiders o bots. El crawler de Google, llamado Googlebot, opera de manera continua, sistemática y masivamente paralela.
El proceso comienza con un conjunto inicial de URLs conocidas, que pueden provenir de varias fuentes: páginas populares previamente indexadas, sitemaps XML enviados por webmasters, nuevos dominios registrados, o enlaces descubiertos en páginas ya rastreadas.
El crawler descarga el contenido HTML de cada página en su lista, pero no se detiene ahí. Analiza el HTML buscando enlaces a otras páginas, que añade a su cola de páginas por visitar (y así es como se mapean y descubren los sitios públicos). Este proceso recursivo permite al crawler descubrir contenido nuevo de manera orgánica, siguiendo la estructura de hipervínculos de la web.
Por su puesto, el crawling tiene su propia complejidad y reglas internas. Googlebot debe tomar decisiones inteligentes sobre qué páginas visitar, con qué frecuencia, y en qué orden. Factores como la autoridad del dominio, la frecuencia de actualización del contenido, la profundidad de la página dentro de la estructura del sitio, y las directivas del archivo robots.txt influyen en estas decisiones.
El archivo robots.txt permite a los administradores de sitios web indicar qué partes de su sitio no deberían ser rastreadas. Aunque Google generalmente respeta estas directivas, es importante entender que robots.txt no es un mecanismo de seguridad; es simplemente una solicitud de cortesía que los crawlers legítimos suelen honrar.
Una vez que el contenido es descargado, comienza el proceso de indexación. Este es mucho más que simplemente almacenar una copia de la página. Google analiza el contenido para entender su temática, relevancia, calidad y relación con otras páginas.
Extrae y procesa el texto visible, los metadatos en el HTML (como el título de la página, meta descripciones, etiquetas alt de imágenes), la estructura del documento (encabezados, párrafos, listas), y los enlaces tanto internos como externos.
El Índice Invertido
El corazón de cualquier motor de búsqueda es su índice invertido. Esta estructura de datos es fundamental para entender cómo funcionan las búsquedas y, por extensión, cómo operan los Google Dorks.
En lugar de mantener un registro que diga "la página A contiene las palabras X, Y, Z", un índice invertido mantiene registros que dicen "la palabra X aparece en las páginas A, B, C, en las posiciones...".
Esta inversión de la relación palabra-documento permite búsquedas extremadamente rápidas incluso en conjuntos de datos masivos. Y como tal, permite saber en que documentos o páginas se encuentran X o Y palabras.
Cuando realizamos una búsqueda simple como "manzanas rojas" (sin comillas), Google "tokeniza" (separa) la consulta en palabras individuales: ["manzanas", "rojas"].
Luego consulta el índice invertido para cada término:
- El término "manzanas" aparece en un conjunto de documentos {D1, D5, D8, D12, D45, D89...}
- El término "rojas" aparece en otro conjunto {D3, D5, D7, D12, D67, D89...}
Recuerda que los Documentos son en realidad páginas web.
El motor luego realiza operaciones de conjunto sobre estos resultados. Para una búsqueda OR (cualquiera de los términos), calcula la unión de los conjuntos (las páginas que contienen la palabra "manzana" o "rojas").
¿De qué depende cuales resultados aparecen primero? En realidad, de muchas cosas, Google aplica algoritmos de ranking que consideran cientos de factores: la proximidad de los términos en el documento, su frecuencia, la autoridad de la página (medida en parte por los enlaces entrantes), la frescura del contenido, la ubicación geográfica del usuario, su historial de búsquedas, y muchos más.
El optimizar un sitio web para que sea uno de los primeros que aparezca con base en lo que Google prioriza es a lo que comúnmente se llama SEO.
Este índice es un sistema distribuido masivo, replicado en miles de servidores alrededor del mundo. Cuando realizas una búsqueda, tu consulta se distribuye a múltiples servidores que procesan diferentes porciones del índice en paralelo, y los resultados se agregan y ordenan antes de presentártelos, todo en una fracción de segundo.
Recuerda: gracias a que Google mantiene este índice invertido, cuando realizas una búsqueda como “manzanas rojas”, el motor no recorre toda la web en tiempo real. En su lugar, consulta su índice previamente construido (con crawling) para ambas palabras.
Primero, identifica en qué documentos (páginas web) aparece cada término. Luego, combina los resultados y evalúa cuáles de esas páginas son más relevantes, aplicando los criterios de calidad definidos por sus algoritmos: la frecuencia y proximidad de las palabras, la autoridad del dominio, la frescura del contenido, la ubicación del usuario, el idioma y muchos otros factores.
En cuestión de milisegundos, Google ordena esos resultados de mayor a menor relevancia y te muestra las páginas que contienen los términos buscados y cumplen mejor con los parámetros de calidad.
El índice invertido funciona como una gigantesca base de datos que permite a Google “saber” en qué lugar del internet indexado se encuentra cada palabra, y recuperar la información con precisión y velocidad.
Google Dorks
Aquí llegamos a un punto crucial que muchos principiantes malinterpretan: los Google Dorks no te dan acceso a información oculta o secreta. No estás "hackeando" Google ni descubriendo una web oscura oculta.
De hecho estás encontrando menos información, pero más precisa (si los usas bien).
Los dorks son simplemente operadores de búsqueda avanzada que te permiten ser más preciso sobre qué subconjunto del índice de Google quieres examinar.
Cuando usas un operador como site:ejemplo.com, NO estás instruyendo a Google para que vaya a rastrear ese sitio en tiempo real. Estás diciéndole que filtre su índice existente para mostrar solo resultados que fueron previamente indexados desde ese dominio.
Cuando usas filetype:pdf, no estás buscando PDFs en Internet; estás filtrando el índice de Google para mostrar solo las entradas que fueron clasificadas como PDF durante el proceso de indexación.
Los Google Dorks trabajan exclusivamente sobre lo que Google ya ha indexado, lo que representa apenas una fracción del contenido total de Internet. Se estima que Google indexa solo entre el 4% y el 10% de todo el contenido web disponible.
El resto, conocido como la "deep web", incluye contenido detrás de formularios de login, bases de datos dinámicas, intranets corporativas, y cualquier contenido explícitamente excluido del rastreo.
Es importante recordar (sobre todo si estás empezando) que deep web no equivale a contenido ilegal; simplemente se trata de información que existe en servidores pero no está disponible públicamente a través del scraping de los motores de búsqueda (por ejemplo: tus fotos en iCloud, documentos privados en Google Drive, archivos de almacenamiento en la nube o conversaciones que permanecen en servidores de aplicaciones).
Por otro lado, cuando hablamos de redes deliberadamente ocultas y no accesibles mediante los protocolos estándar nos referimos a la darknet: un subconjunto distinto donde se alojan servicios escondidos (por ejemplo sitios .onion accesibles vía Tor). En la darknet suelen encontrarse foros y mercados que buscan anonimato, pero conviene distinguirla claramente de la deep web, que es en gran parte simplemente contenido no indexado.
Cada operador de Google Dorking actúa como un filtro que reduce el conjunto de resultados. Si pensamos en el índice de Google como una gigantesca base de datos, los dorks son como cláusulas WHERE en una consulta SQL, permitiéndonos ser cada vez más específicos sobre qué registros queremos ver.
La potencia de esto surge de la combinación de múltiples operadores, creando filtros complejos que pueden identificar patrones muy específicos de información.
Operadores Fundamentales
Los operadores de Google funcionan porque, durante el proceso de indexación, el motor no solo almacena el texto visible de una página, sino que estructura y clasifica su contenido en campos separados dentro de su índice. Esta arquitectura de campos permite ejecutar búsquedas con precisión quirúrgica sobre dimensiones específicas de los documentos indexados.
Antes de examinar los operadores de campo, debemos comprender el operador más fundamental: las comillas dobles.
El Operador de Comillas Dobles: Búsqueda de Secuencia Exacta
Las comillas dobles representan la diferencia entre una búsqueda aproximada y una búsqueda de secuencia exacta. Y es en realidad uno de los operadores más importantes y uno de mis favoritos.
Cuando ejecutamos una búsqueda sin comillas, como vulnerabilidades apache, Google tokeniza la consulta en términos individuales: ["vulnerabilidades", "apache"].
Búsqueda normal sin comillas:

El motor consulta su índice invertido para cada término de forma independiente, retornando páginas que contengan ambos términos en cualquier ubicación y orden dentro del documento.
Una página que contenga "Apache presenta múltiples vulnerabilidades" y otra que diga "las vulnerabilidades más comunes incluyen fallos en Apache" califican ambas como resultados válidos.
Los algoritmos de ranking posteriormente evalúan factores como la proximidad entre términos, su frecuencia y ubicación en el documento, pero la búsqueda base no exige ninguna relación posicional específica entre ellos.
¿Entonces cómo aplicamos una búsqueda exacta?
El operador de comillas dobles transforma esto en una búsqueda de secuencia exacta. - Sólo encontrarás resultados donde Apache esté después de la palabra vulnerabilidades, y es replicable para cualquier otra cadena de texto como nombres ;)
Al ejecutar "vulnerabilidades apache", instruimos al motor para localizar únicamente documentos donde estos términos aparezcan consecutivamente y en el orden especificado.
Búsqueda con comillas dobles:

La página con "Apache presenta múltiples vulnerabilidades" ya NO califica porque los términos no están presentes como indicamos en las comillas dobles (nota que entre apache y vulnerabilidades que son los términos que indicamos entre comillas dobles hay más palabras, lo que provoca que no sea apto para un resultado de comillas dobles).
En cambio un resultado cuyo contenido sea: "las vulnerabilidades apache más recientes" aplicaría como resultado ya que "vulnerabilidades apache" - apache después de la palabra vulnerabilidades
Es justo lo que pedimos en nuestra búsqueda con comillas aplicadas.
Esta capacidad depende de una característica del índice de Google: el almacenamiento de información posicional.
Normalización y Limitaciones
Google normaliza el texto durante la indexación. El motor ignora mayúsculas (case-insensitive) y procesa signos de puntuación como delimitadores o los elimina completamente.
Una búsqueda de "servidor web" coincidirá con "Servidor Web", "SERVIDOR WEB", o "servidor-web" porque las variaciones se normalizan a la misma secuencia de tokens durante la indexación.
Los apóstrofos y guiones típicamente se tratan como espacios, por lo que "don't" puede coincidir con "don t". Esta normalización es una decisión de diseño para mejorar la recuperación de información, pero limita la capacidad de búsqueda absolutamente literal de secuencias que contengan caracteres especiales.
Otros Operadores
Durante el proceso de indexación, Google realiza un análisis estructural del documento. Cuando Googlebot descarga una página HTML, no la procesa como un bloque monolítico de texto sino que ejecuta múltiples extracciones de información y posteriormente las clasifica, almacenando diferentes componentes en campos dentro del índice.
Esta segmentación es lo que permite que los operadores de campo actúen como filtros precisos.
El proceso de extracción incluye:
- Campo TITLE: Contenido de la etiqueta
<title>del documento HTML - Campo URL: URL completa incluyendo protocolo, dominio, subdominios, ruta y parámetros
- Campo DOMAIN: Dominio base extraído de la URL
- Campo BODY_TEXT: Texto visible renderizado del contenido principal
- Campo FILETYPE: Tipo de archivo identificado por extensión y MIME type
Cada operador de campo funciona como una cláusula de filtrado que consulta exclusivamente una dimensión específica de esta estructura dentro de lo conocido por Google.
intitle: - Este operador filtra el campo TITLE del índice. Cuando ejecutamos intitle:configuracion, Google examina únicamente el contenido almacenado en el campo título de cada documento indexado, ignorando completamente el cuerpo del texto, la URL, y cualquier otro campo. Esto reduce drásticamente el espacio de búsqueda porque el campo título es relativamente pequeño comparado con el contenido completo del documento.
Ejemplo de uso:
intitle:"password reset" site:github.com

Esta consulta localiza páginas en GitHub cuyo título contiene la frase exacta "password reset", útil para identificar funcionalidades de restablecimiento de contraseñas en repositorios públicos.
Como puedes ver, los resultados contienen el texto "password reset" en el título del sitio:

inurl: - Filtra el campo URL completo. Este operador examina la estructura de la dirección web, incluyendo subdominios, rutas, nombres de archivo y parámetros de consulta. Es realmente efectivo para identificar patrones estructurales en la organización de sitios web.
Ejemplo de uso:
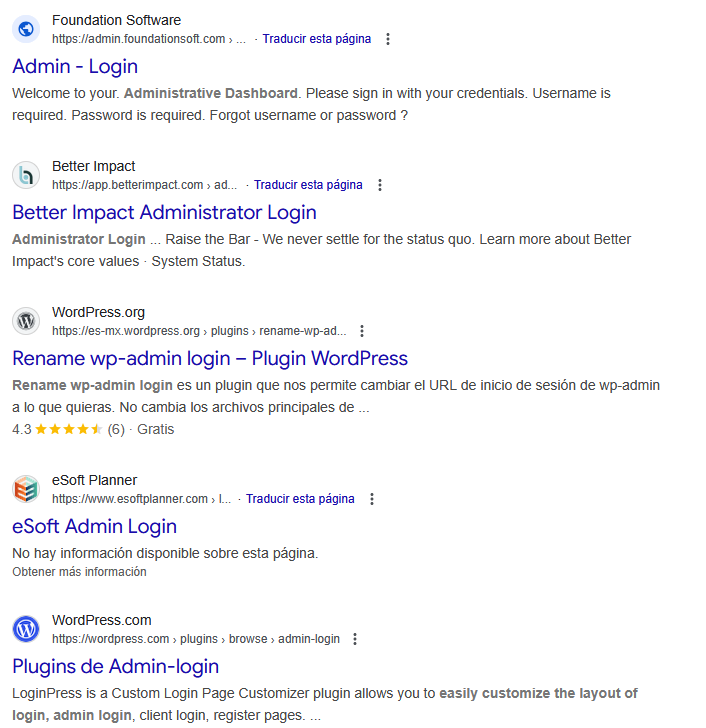
inurl:admin inurl:login

Localiza páginas cuya URL contiene tanto "admin" como "login", típicamente paneles de administración. Rutas como /admin/login.php o /portal/admin-login calificarían como resultados.
En este caso, todos los resultados tendrán presente las palabras admin y login en la URL.
intext: - Aplica el filtro al campo BODY_TEXT, buscando términos específicamente en el contenido textual visible del documento. Excluye títulos, URLs y metadatos estructurados. Este operador es útil cuando necesitamos confirmar que un término aparece en el contenido sustantivo del documento, no meramente en elementos estructurales o de títulos.
Ejemplo de uso:
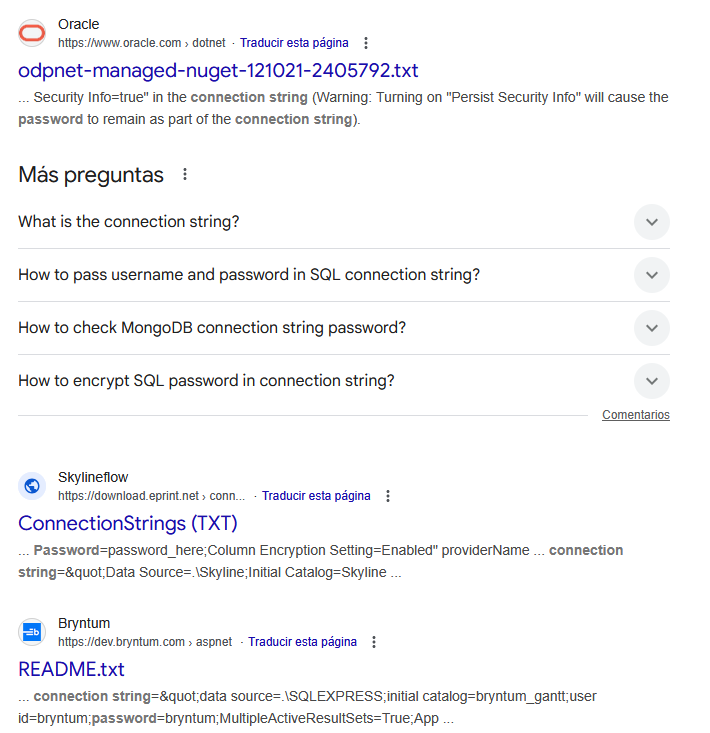
intext:"connection string" intext:"password=" filetype:txt

Busca archivos de texto que contengan tanto "connection string" como "password=" en su contenido, potencialmente identificando archivos de configuración expuestos inadvertidamente.
Para la búsqueda: intext:"connection string" intext:"password=" filetype:txt . Todos los resultados tendrán en la sección de texto las palabras indicadas entre comillas dobles: "connection string" y "password=" , además de ser un documento de tipo TXT
site: - Este operador especial filtra por el campo DOMAIN. Recuerda que site: no instruye a Google para rastrear un dominio en tiempo real; simplemente limita los resultados del índice existente a documentos previamente indexados desde ese dominio o subdominio específico.
El operador site: admite miles de patrones, en realidad solo es cuestión de que incluyas el nombre de dominio del sitio donde te interesa buscar:
site:ejemplo.com # Dominio completo y todos sus subdominios
site:blog.ejemplo.com # Subdominio específico únicamente
site:.edu # TLD completo (instituciones educativas)
site:.gob.mx # TLD geográfico (gobierno mexicano)
site:ejemplo.com -site:www.ejemplo.com # Excluir subdominio específico
Ejemplo de uso:
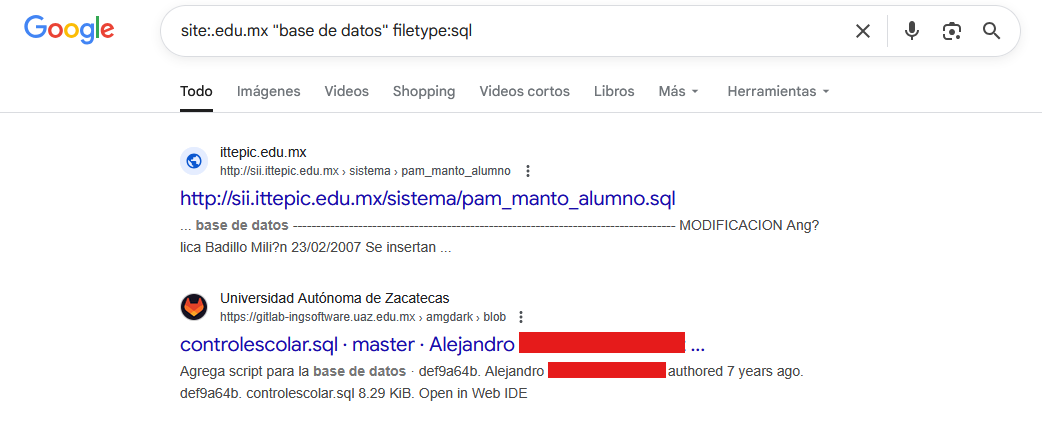
site:.edu.mx "base de datos" filetype:sql

Localiza archivos SQL en instituciones educativas mexicanas que contengan "base de datos" en su contenido o metadata, potencialmente identificando respaldos de bases de datos expuestos.
Como puedes ver, los resultados son únicamente dentro de dominios "edu.mx" y el tipo de archivo identificado es una base de datos sql.
Otro ejemplo de esto sería :
site:.gob.mx "curp" "correo" filetype:pdf

En este caso los resultados estarán limitados al dominio gob.mx , contendrán las palabras "curp" y correo y los resultados deben ser PDFs, lo que podría permitir identificar documentos PDF con datos personales.
filetype: - Filtra por el campo FILETYPE. Durante la indexación, Google identifica el tipo de archivo mediante múltiples señales: la extensión en la URL, el Content-Type HTTP header enviado por el servidor, y análisis del contenido real del archivo.
Google puede extraer e indexar el contenido textual de numerosos formatos de archivo estructurados.
Tipos de archivo comúnmente indexados:
- Documentos:
pdf,doc,docx,odt,rtf,txt - Hojas de cálculo:
xls,xlsx,csv,ods - Presentaciones:
ppt,pptx,odp - Código fuente:
php,asp,jsp,py,java,js - Configuración:
xml,conf,ini,yaml,json - Bases de datos:
sql,db,mdb
Ejemplo de uso:
site:gob.mx filetype:xls intext:"confidencial"
Esta consulta localiza hojas de cálculo Excel en sitios gubernamentales mexicanos que contengan la palabra "confidencial" en su contenido indexado.

Como puedes ver, funciona. Los resultados son XLS (Excel), están alojados en gob.mx y contienen la palabra confidencial:

Recuerda que estamos identificando información pública, así que los resultados anteriores incluso si tienen la palabra "confidencial" son sitios que están públicamente disponibles y Google conoce.
Operadores Adicionales
related: - Identifica sitios que Google considera similares o relacionados con una URL específica. El motor evalúa similitud temática, perfiles de enlaces entrantes y patrones de tráfico.
related:nytimes.com
Retornará otros sitios de noticias que Google considera relacionados al New York Times, como washingtonpost.com, theguardian.com, etc.
AROUND(X) - Operador de proximidad que localiza documentos donde dos términos aparecen dentro de X palabras de distancia. Más flexible que comillas dobles pero más preciso que un AND simple.
"ciberseguridad" AROUND(5) "infraestructura crítica"
Encuentra páginas donde estos términos aparecen separados por máximo 5 palabras, permitiendo texto intermedio pero garantizando relación contextual cercana.
before: y after: - Filtros temporales que limitan resultados a contenido publicado o modificado en rangos de fechas específicos. Formato: YYYY-MM-DD.
site:gob.mx "licitación" after:2024-01-01 before:2024-12-31
Busca menciones de "licitación" en sitios gubernamentales mexicanos durante el año 2024.
Nota que las fechas coinciden con el rango especificado por nuestros operadores before y after:

Operador OR - Permite búsquedas disyuntivas. Debe escribirse en mayúsculas o usar el símbolo pipe |.
site:.edu (ciberseguridad OR "cyber security" OR "information security")
Localiza cualquiera de los términos en instituciones educativas.
Operador menos (-) - Excluye términos específicos de los resultados. No debe haber espacio entre el guion y el término excluido.
vulnerabilidades java -android
Busca información sobre vulnerabilidades Java excluyendo resultados relacionados con Android.
ext: - Sinónimo de filetype:, funciona idénticamente. Se encuentra en documentación más antigua pero sigue operativo.
ext:sql "CREATE TABLE"
inanchor: - Busca términos en el anchor text (texto de anclaje) de enlaces que apuntan a páginas. Útil para análisis de perfiles de enlaces y entender cómo otros sitios referencian un recurso.
inanchor:"guía completa" ciberseguridad
Encuentra páginas que tienen enlaces entrantes cuyo anchor text contiene "guía completa" y están relacionadas con ciberseguridad.
Combinación de Operadores
Si bien de los ejemplos previos ya has visto como podemos aplicar combinaciones de Google Dorks es importante que lo veamos a mayor detalle para que lo tengas claro. La potencia real del Google Dorking viene de la combinación de múltiples operadores.
Realmente no es tan útil saber todos los PDFs conocidos por Google (búsqueda que podríamos hacer simplemente escribiendo en nuestra barra de búsqueda filetype:pdf) , pero lo que si es útil es conocer es todos los PDF que contengan la palabra confidencial dentro de un sitio web de nuestro interés (búsqueda que podríamos hacer con site:dominio.com "confidencial" filetype:pdf).
Puedes verlo como que cada operador actúa de forma similar a una cláusula WHERE en una consulta SQL, y combinarlos equivale a aplicar condiciones conjuntivas que reducen el conjunto de resultados (volviendo más preciso lo que buscamos).
Considera esta consulta:
site:gob.mx filetype:xls intext:"confidencial" -inurl:public
El motor procesa esto mediante filtrado secuencial:
- Primer filtro (
site:gob.mx): Del índice completo de Google (cientos de miles de millones de páginas), reduce a documentos del dominio gob.mx - Segundo filtro (
filetype:xls): Del subconjunto anterior, retiene solo archivos Excel. Si el 1% de las páginas gubernamentales son archivos Excel, reducimos a ~10,000-20,000 documentos - Tercer filtro (
intext:"confidencial"): De estos archivos Excel, filtra solo aquellos cuyo contenido contiene "confidencial". Si esto representa el 0.5%, llegamos a ~50-100 documentos - Cuarto filtro (
-inurl:public): Excluye resultados cuya URL contenga "public". Si el 20% tiene esta palabra en la URL, el resultado final es ~40-80 documentos
Cada filtro reduce drásticamente el espacio de búsqueda. Esta reducción transforma la búsqueda de información en un proceso quirúrgico capaz de identificar conjuntos extremadamente específicos de documentos entre el vasto índice de Google.
Ejemplo: Identificación de Paneles Administrativos Expuestos
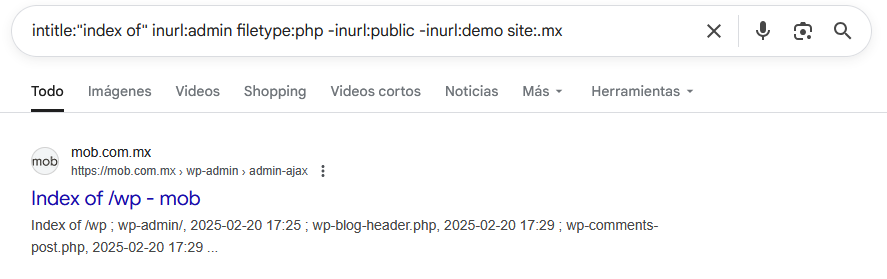
intitle:"index of" inurl:admin filetype:php
-inurl:public -inurl:demo site:.mx
Esta búsqueda localiza:
- Páginas con "index of" en el título (listados de directorios)
- Con "admin" en la URL
- Archivos PHP específicamente
- Excluyendo directorios públicos o demos
- Limitado a sitios mexicanos - debido a site:.mx
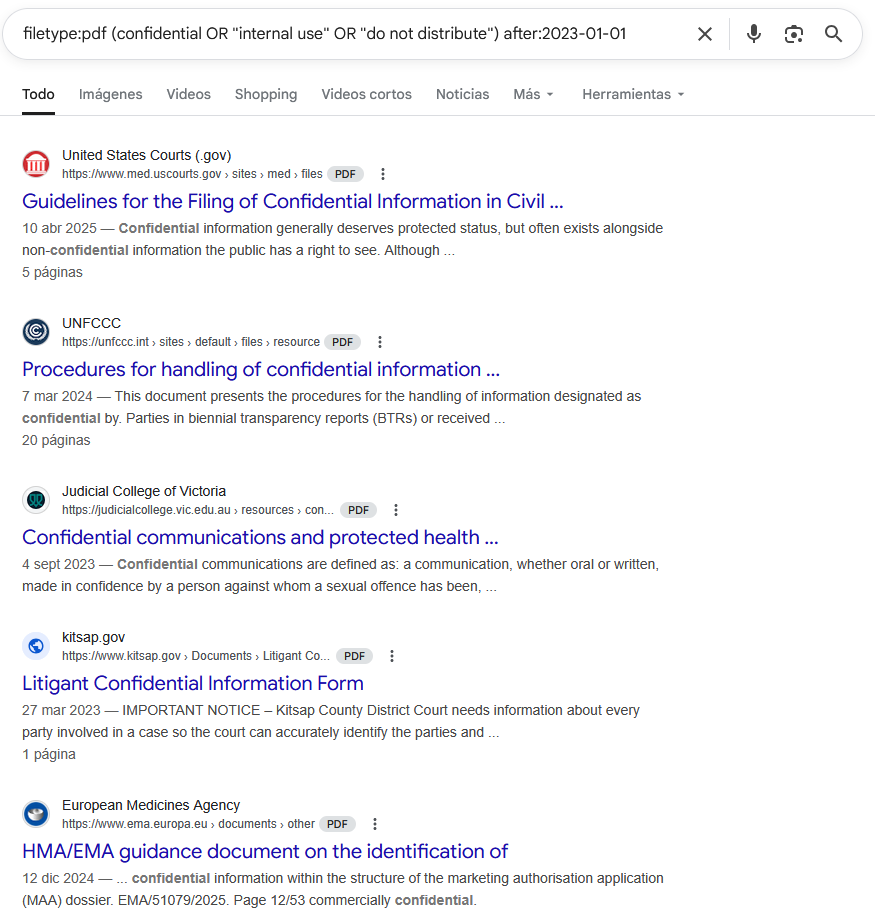
Ejemplo: Análisis de Divulgación de Información en PDFs Corporativos
site:empresa.com filetype:pdf
(confidential OR "internal use" OR "do not distribute")
after:2023-01-01
Identifica documentos PDF en un dominio corporativo que contengan términos de clasificación de información y fueron indexados recientemente (después del 2023-01-01).
Los Google Dorks operan exclusivamente sobre el índice existente de Google. No inician rastreos en tiempo real ni acceden a contenido no indexado. El índice de Google representa aproximadamente el 4-10% del contenido web total. El resto constituye la "deep web" (contenido detrás de autenticación, bases de datos dinámicas, contenido bloqueado por robots.txt) y la "dark web" (redes como Tor deliberadamente ocultas).
Los operadores tampoco garantizan resultados. Google puede limitar el número de resultados mostrados para consultas muy específicas, y ciertos operadores pueden comportarse de manera inconsistente dependiendo de la complejidad de la consulta y la carga del sistema.
La estructura de campos separados en el índice de Google y la información posicional almacenada son los fundamentos técnicos que hacen posible este nivel de precisión. Cada operador no es un "truco" sino una interfaz documentada para consultar dimensiones específicas de una base de datos distribuida masivamente.
Ego Surfacing y el Pensamiento Analítico
Antes de continuar, es fundamental comprender un principio que determina la efectividad real de cualquier búsqueda avanzada: los Google Dorks son simplemente herramientas de filtrado.
Su utilidad depende enteramente de la capacidad del investigador para entender las características, estructura y contexto de la información que busca. Conocer los operadores sin comprender cómo se manifiesta la información en el mundo real es equivalente a tener un bisturí sin conocimientos de anatomía.
Y esto es lo que sucede con muchos pentesters que aprenden a pegar algunos dorks y por dicha acción creen que saben OSINT.
De hecho tenemos un blog completo dedicado al tema de la mentalidad al buscar y la futilidad de las herramientas si no sabes realmente lo que estás haciendo:

Esta realidad se hace evidente cuando aplicamos Google Dorking para buscar información sobre nosotros mismos, una práctica conocida como ego surfacing.
Este ejercicio no solo es útil para monitorear nuestra presencia digital, sino que ilustra perfectamente por qué el análisis previo de la información es más importante que el conocimiento de operadores.
La recomendación es que apliques las siguientes búsquedas usando tus propios datos como nombres, correos, teléfonos, etc. Podrías llevarte una gran sorpresa y descubrir los datos que hay sobre ti en internet :)
Búsqueda de Información Personal
Consideremos la búsqueda más básica: localizar menciones de nuestro propio nombre. Una persona llamada Juan Pérez Sánchez podría ejecutar la búsqueda en Google:
"juan perez sanchez"
Esta búsqueda localizará documentos donde el nombre aparece en ese orden específico.
Sin embargo, un investigador que comprende el contexto regional de América Latina reconoce una limitación con esta búsqueda: muchos documentos oficiales, registros públicos, listas administrativas y sistemas gubernamentales ordenan los nombres comenzando por el apellido paterno. Por lo tanto, la búsqueda complementaria (comenzando por apellidos):
"perez sanchez juan"
Producirá un conjunto de resultados completamente diferente, potencialmente revelando registros en padrones electorales, listas de empleados en entidades gubernamentales, documentos oficiales y actas, registros académicos históricos, y certificaciones profesionales.
Esta variación no es algo que debas ignorar; en contextos latinoamericanos, puede representar la diferencia entre encontrar el 30% o el 70% de la información disponible sobre una persona. El operador de comillas dobles no cambió, pero nuestra comprensión de cómo se estructura la información en diferentes contextos culturales y administrativos sí modificó radicalmente los resultados.
Podemos refinar aún más aplicando filtros geográficos y de tipo de documento:
"perez sanchez juan" site:.gob.mx filetype:pdf
O limitar a instituciones educativas donde probablemente aparezcan registros académicos:
"juan perez sanchez" OR "perez sanchez juan" site:.unam.mx
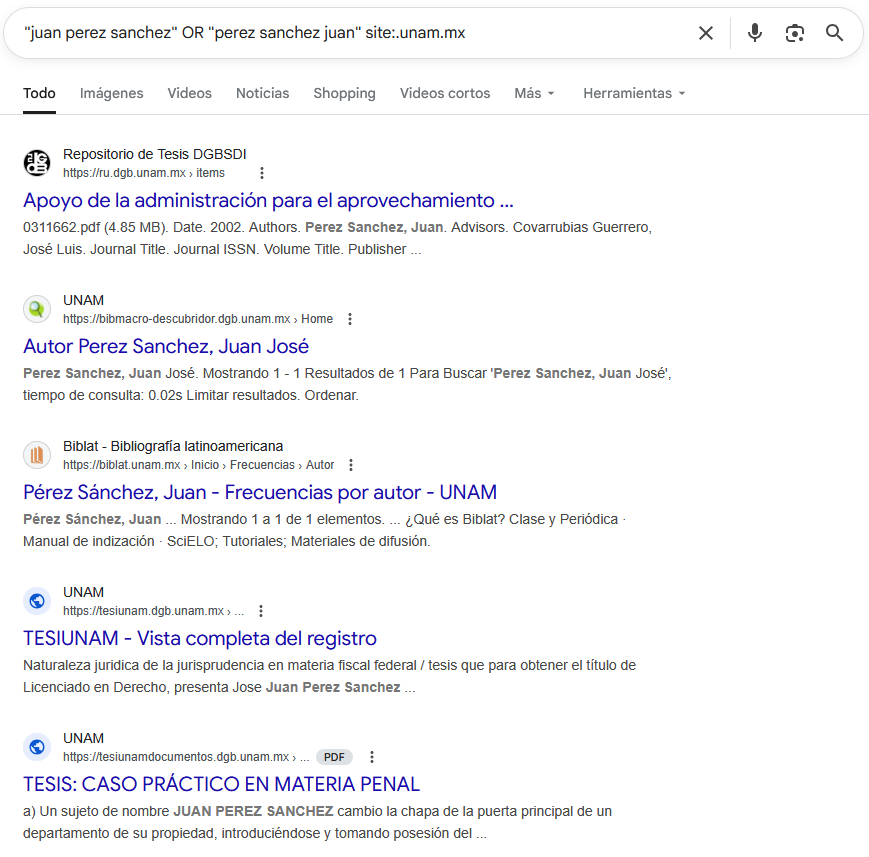
Antes de construir la consulta, debemos preguntarnos cómo se registra, almacena y presenta típicamente este tipo de información en los contextos relevantes.
Búsqueda de Identificadores: Anticipando Variaciones de Formato
Los identificadores personales presentan un desafío adicional: pueden aparecer en múltiples formatos según el sistema que los registró, la interfaz de usuario que los capturó, o las preferencias del transcriptor.
Números de teléfono
Un número de teléfono mexicano puede aparecer en múltiples variantes: +52 55 1234 5678, 5512345678, 55-1234-5678, (55) 1234-5678, o 52 55 1234 5678. Una búsqueda efectiva debe anticipar estas variaciones. Para localizar un número específico, podríamos construir una consulta disyuntiva (OR):
"+52 55 1234 5678" OR "5512345678" OR "55-1234-5678" OR "(55) 1234-5678"
Sin embargo, si buscamos el número en un contexto específico como filtraciones de bases de datos, podemos combinar con operadores de archivo:
"5512345678" filetype:csv OR filetype:xls OR filetype:txt
O si sospechamos que el número puede aparecer en redes sociales o foros:
"55 1234 5678" (site:facebook.com OR site:twitter.com OR site:linkedin.com)
Correos electrónicos
Los correos electrónicos son generalmente más consistentes en formato, pero el contexto de aparición varía. Esta búsqueda excluye el sitio corporativo oficial (donde el correo aparecerá legítimamente) y se enfoca en apariciones en otros contextos como filtraciones de datos, foros, o perfiles públicos:
"juan.perez@empresa.com" -site:empresa.com
Para identificar si un correo aparece en bases de datos expuestas:
"juan.perez@empresa.com" (filetype:sql OR filetype:csv OR filetype:txt OR filetype:log)
O simplemente buscar si aparece en algún lugar de internet conocido por Google:
"juan.perez@empresa.com"
Identificadores únicos regionales
En América Latina, diversos países utilizan identificadores únicos de ciudadanos con formatos específicos.
El CURP (Clave Única de Registro de Población) en México tiene un formato alfanumérico de 18 caracteres. Esta búsqueda podría revelar si el CURP aparece en documentos oficiales indexados públicamente:
"PXSJ850315HDFRXN09" filetype:pdf site:.gob.mx
También podríamos buscar en hojas de cálculo administrativas expuestas inadvertidamente:
"PXSJ850315HDFRXN09" (filetype:xls OR filetype:xlsx OR filetype:csv)
La Cédula de Ciudadanía en Colombia es un identificador numérico. Dado que los números de cédula son puramente numéricos, es importante combinar con contexto adicional para evitar falsos positivos:
"1023456789" site:.gov.co filetype:pdf
O con términos contextuales:
"1023456789" (cedula OR "cédula" OR "documento") site:.gov.co
La búsqueda de identificadores únicos es particularmente crítica para detectar filtraciones de datos personales.
Protección de Marca y Detección de Actividad Ilícita - ¿Cómo usamos los Dorks en Purpl3 Cult?
El mismo principio de "comprender la estructura de la información antes de buscarla" se aplica a contextos comerciales y de cumplimiento normativo.
Detección de productos falsificados o comercio irregular
Como sabrás, nuestros clientes normalmente son farmacéuticas y empresas transnacionales de alcohol o tabaco, así que consideremos un caso de medicamentos de prescripción que frecuentemente se falsifican o comercializan fuera de canales regulados.
Ozempic (semaglutida), un medicamento para diabetes que se ha popularizado para pérdida de peso, es un ejemplo donde la venta no autorizada representa riesgos significativos (y una oportunidad para nosotros para vender servicios de OSINT a las grandes empresas).
Dado que comprendemos cómo operan los mercados informales en línea sabemos que Facebook Groups es un vector común para este tipo de comercio.
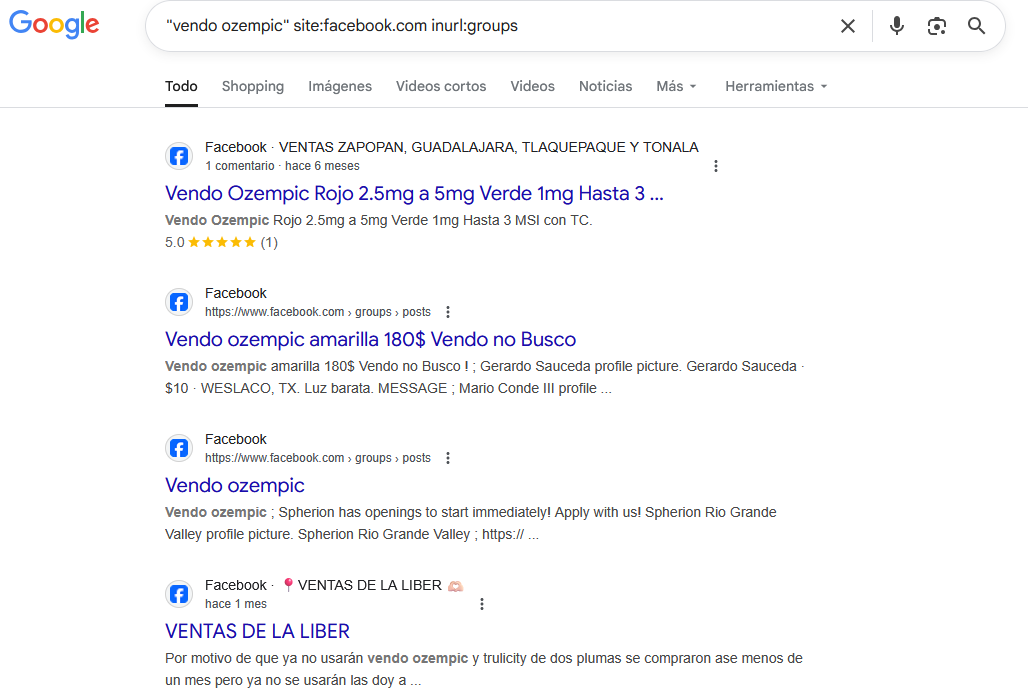
Una simple búsqueda como:
"vendo ozempic" site:facebook.com inurl:groups
Permite localizar publicaciones en grupos de Facebook que contienen la frase exacta "vendo ozempic", indicando intentos de venta directa que probablemente no cumplen con regulaciones farmacéuticas, lo que nos permite monetizar y ofrecer investigaciones más profundas y lograr desanonimizar y facilitar una sanción al infractor.
Podríamos expandir esto para capturar variaciones lingüísticas y errores ortográficos comunes:
(vendo OR venta OR "se vende") (ozempic OR semaglutida) site:facebook.com
Para productos de alcohol o tabaco falsificados, podríamos buscar en marketplaces y redes sociales. El operador -site:johnniewalker.com excluye el sitio oficial, enfocándonos en distribuidores potencialmente no autorizados:
"whisky johnnie walker" ("venta" OR "vendo") (site:facebook.com OR site:instagram.com OR site:mercadolibre.com.mx) -site:johnniewalker.com
Investigación de fraudes y phishing
Los investigadores de seguridad utilizan dorks para localizar sitios de phishing que imitan marcas legítimas. Esta búsqueda localiza páginas que tienen "login" en el título y "paypal" en la URL pero que no son los dominios oficiales de PayPal, potencialmente identificando sitios de phishing:
intitle:"login" inurl:paypal -site:paypal.com -site:paypal.mx
Como puedes ver, fácilmente podemos identificar sitios falsos que suplantan a Paypal:

Identificación de Configuraciones y Credenciales Expuestas
Un área crítica donde el pensamiento analítico previo es esencial es la identificación de información sensible expuesta inadvertidamente. Los desarrolladores y administradores de sistemas ocasionalmente suben archivos de configuración, respaldos de bases de datos, o logs a servidores web sin protección adecuada.
Archivos de configuración con credenciales
Los archivos .env (utilizados en aplicaciones web modernas para almacenar variables de entorno) frecuentemente contienen credenciales de bases de datos. Esta búsqueda puede revelar archivos de configuración expuestos que contienen credenciales activas:
filetype:env "DB_PASSWORD" "DB_USERNAME"
Para archivos de configuración de PHP:
filetype:ini "password=" "host="
Respaldos de bases de datos
Los respaldos SQL expuestos son una fuente común de filtraciones:
filetype:sql "INSERT INTO" "users"
O más específicamente para respaldos de WordPress:
filetype:sql "wp_users" "user_pass"
Logs con información sensible
Los archivos de log pueden contener tokens de acceso, API keys, o información de sesión. La exclusión de GitHub evita resultados de repositorios de código abierto donde los logs de ejemplo son comunes:
filetype:log "password" "username" -github.com
Análisis Antes de Ejecución -PIENSA
Todos estos ejemplos ilustran el mismo principio: la efectividad de Google Dorking no proviene de memorizar operadores, sino de la capacidad para analizar cómo se estructura, almacena y presenta la información que buscamos.
Antes de construir cualquier consulta, debes preguntarte:
¿Qué características tiene la información que busco?
¿Es un formato estandarizado como CURP, RFC, o números de teléfono? ¿Tiene variaciones regionales o culturales, como el orden de nombres en documentos oficiales? ¿Existen múltiples representaciones del mismo dato, como diferentes formatos de números telefónicos?
¿En qué contextos o tipos de documentos probablemente aparece esta información?
¿Se encuentra típicamente en documentos oficiales como PDFs gubernamentales? ¿En bases de datos administrativas exportadas como Excel o CSV? ¿En publicaciones en redes sociales? ¿En archivos de configuración técnicos expuestos inadvertidamente?
¿Qué términos contextuales acompañan típicamente esta información?
¿Aparece junto a palabras específicas como "vendo", "cédula", o "password"? ¿Existe jerga o terminología específica del dominio que pueda usarse como filtro adicional?
¿Qué dominios o tipos de sitios son más probables para hospedar esta información?
¿Sitios gubernamentales con dominios .gob o .gov? ¿Instituciones educativas con .edu? ¿Redes sociales específicas como Facebook, LinkedIn, o Twitter? ¿Marketplaces regionales?
Los Google Dorks proporcionan las herramientas de filtrado, pero el investigador (tú, siempre y cuando apliques el esfuerzo necesario y no seas el clásico perdedor que se rinde a los 3 días) debe proporcionar la inteligencia sobre qué filtrar y cómo.
Un principiante puede conocer todos los operadores y aún así obtener resultados pobres si no comprende la naturaleza de la información que busca o ni siquiera entender en qué situaciones podría utilizar Google Dorks.
Un investigador experimentado puede construir consultas altamente efectivas con solo unos pocos operadores básicos.
Esta habilidad analítica se desarrolla con práctica, conocimiento del dominio, y pensamiento crítico sobre cómo los sistemas almacenan y presentan información.
Los ejemplos presentados aquí son precisamente eso: ejemplos.
Es tu deber desarrollar la capacidad de pensar independientemente sobre las características únicas de la información que busca en su contexto específico, adaptando los operadores a esas características identificadas.
Por cierto, en nuestro arsenal tuvimos varias clases destinadas al pensamiento analítico en el campo de la inteligencia ;)

Los Google Dorks no son herramientas de hacking en el sentido cinematográfico o flashy del término. No rompen sistemas ni burlan medidas de seguridad.
Son simplemente una forma sofisticada de interrogar el índice público de Google, separando la señal del ruido en el vasto océano de información indexada. Su poder no está en en mostrar información oculta, sino en hacer visible lo que siempre estuvo ahí pero perdido entre millones de resultados irrelevantes.
El dominio efectivo de los Google Dorks no viene de memorizar listas de comandos, sino de entender profundamente cómo funcionan los motores de búsqueda, cómo se estructura y se expone la información en la web, y realmente pensar: ¿Qué características tiene lo que busco?.
Recursos y Materiales
Tabla de Referencia Rápida: Google Dorks
A continuación se presenta una tabla de referencia que muestra los operadores más útiles de Google Dorking.
Esta tabla está diseñada para servir como guía rápida durante investigaciones, pero recuerda que la efectividad real proviene de comprender el contexto y estructura de la información que buscas, no de memorizar operadores.
Puedes descargar esta tabla en formato PDF para tenerla a la mano cuando quieras solo debes registrarte aquí (el contenido es gratis, solo debes poner $0 en la parte de cantidad a pagar):

| Operador | Uso | Ejemplo |
|---|---|---|
" " |
Búsqueda de secuencia exacta. Los términos deben aparecer consecutivamente y en el orden especificado. | "apache vulnerabilities 2024" |
site: |
Limita resultados a un dominio, subdominio o TLD específico. | site:gob.mx "licitación" |
filetype: |
Filtra resultados por tipo de archivo específico. | filetype:pdf "manual usuario" |
ext: |
Sinónimo de filetype:, funciona idénticamente. |
ext:xls "presupuesto" |
intitle: |
Busca términos específicamente en el título de la página. | intitle:"index of" backup |
allintitle: |
Todos los términos especificados deben aparecer en el título. | allintitle:admin panel login |
inurl: |
Busca términos en la URL de la página. | inurl:admin inurl:config |
allinurl: |
Todos los términos especificados deben aparecer en la URL. | allinurl:admin config php |
intext: |
Busca términos en el contenido textual del cuerpo del documento. | intext:"connection string" filetype:txt |
allintext: |
Todos los términos especificados deben aparecer en el texto del documento. | allintext:username password database |
inanchor: |
Busca términos en el anchor text (texto de enlaces) que apuntan a páginas. | inanchor:"click here" download |
OR |
Operador lógico OR (debe escribirse en mayúsculas). Busca páginas que contengan cualquiera de los términos. | (pdf OR doc OR xls) "confidencial" |
- |
Excluye términos o sitios de los resultados. No debe haber espacio después del guion. | java vulnerabilities -android |
* |
Comodín que representa cualquier palabra o frase. | "comprar * en línea" |
AROUND(X) |
Busca dos términos que aparezcan dentro de X palabras de distancia entre sí. | "ciberseguridad" AROUND(5) "infraestructura" |
before: |
Limita resultados a contenido publicado antes de una fecha específica (formato YYYY-MM-DD). | site:gob.mx "covid" before:2020-12-31 |
after: |
Limita resultados a contenido publicado después de una fecha específica (formato YYYY-MM-DD). | "breach" after:2024-01-01 |
cache: |
Muestra la versión en caché de Google de una página específica. | cache:ejemplo.com/articulo |
related: |
Encuentra sitios relacionados o similares a una URL específica. | related:nytimes.com |
Ejemplos de Consultas Compuestas
| Objetivo | Consulta |
|---|---|
| Archivos Excel con información sensible en sitios gubernamentales | site:.gob.mx filetype:xls (confidencial OR reservado OR "datos personales") |
| Paneles de administración expuestos en sitios mexicanos | intitle:"admin panel" OR intitle:"login" inurl:admin site:.mx -site:github.com |
| Archivos de configuración con credenciales | filetype:env "DB_PASSWORD" OR filetype:ini "password=" -github.com |
| Documentos PDF recientes sobre licitaciones | site:gob.mx "licitación" filetype:pdf after:2024-01-01 |
| Respaldos de bases de datos SQL expuestos | filetype:sql "INSERT INTO" ("users" OR "usuarios") -site:github.com |
| Búsqueda de información personal propia | "juan perez sanchez" OR "perez sanchez juan" (site:.gob.mx OR site:.edu.mx) |
| Detección de venta irregular de medicamentos | "vendo ozempic" (site:facebook.com OR site:mercadolibre.com.mx) inurl:groups |
| Archivos de log con información sensible | filetype:log (password OR token OR "api key") -github.com |
| Páginas de login que no son del dominio oficial | intitle:"login" inurl:paypal -site:paypal.com -site:paypal.mx |
| Documentos con CURPs expuestos | "CURP" filetype:pdf OR filetype:xls site:.gob.mx |
Esta tabla debe usarse como punto de partida, no como lista exhaustiva. La creatividad en la combinación de operadores y la comprensión del contexto de la información buscada son los factores determinantes del éxito en Google Dorking.

Si te interesa el tema de OSINT aplicado a pentest, la GHDB contiene cientos de operadores de dorks que te permiten identificar desde bases de datos, archivos de configuración hasta posibles servidores vulnerables:
